In this class, we were asked to write an MLA style paper on a topic we were interested in,
so I wrote an essay discussing the benefits and potential threats of the release of pre-trained deep learning models
and the potential release strategies for deep learning models that might cause negative social impacts.
You can read my essay
here .
A strictly formatted MLA paper is ideal for serious academic discussions.
Whether you are a scholar in the field of AI or not,
as long as you want to discuss the issue of the release of pre-trained deep learning models seriously,
I welcome you to read
my paper .
However, a scholarly paper is not always ideal for any kinds of arguments.
The way one delivers his or her arguments should highly depend on his or her audience and purpose.
For example, a BuzzFeed article might be suitable if one just wants to introduce the concept of deep learning to ordinary people.
Probably for this reason, in addition to writing an academic essay, on
English 125: College Writing ,
we were also asked to convert our paper to another genre, where we should try to present our arguments in a different way, to different audiences, or for a different purpose.
For this assignment, I chose to make this webpage.
I don't know if anyone besides my professor for this class will read this webpage.
However, if you are not my English professor,
and you happen to be reading this webpage,
I expect you to be a person who are familiar with deep learning,
familiar with the crazily increasing cost of training current deep learning models,
and familiar with OpenAI and their policy on their GPT and Dall-E.
You might be worried about not having enough computation sources for training your deep learning model.
You might feel dissatisfied with OpenAI's withhold of their models, just like what I used to do.
You might also be comfortable reading scholarly paper.
However, in this webpage, I want to share my research with you in a casual way.
Intro
Lorem ipsum dolor sit amet, consectetur et adipiscing elit. Praesent eleifend dignissim arcu, at eleifend
sapien imperdiet ac. Aliquam erat volutpat. Praesent urna nisi, fringila lorem et vehicula lacinia quam.
Integer sollicitudin mauris nec lorem luctus ultrices. Aliquam libero et malesuada fames ac ante ipsum
primis in faucibus. Cras viverra ligula sit amet ex mollis mattis lorem ipsum dolor sit amet.
Why Releasing Pre-trained
Deep Learning Models is
Important and Beneficial
Context: The Cost of Training Deep Learning Models is Growing Rapidly
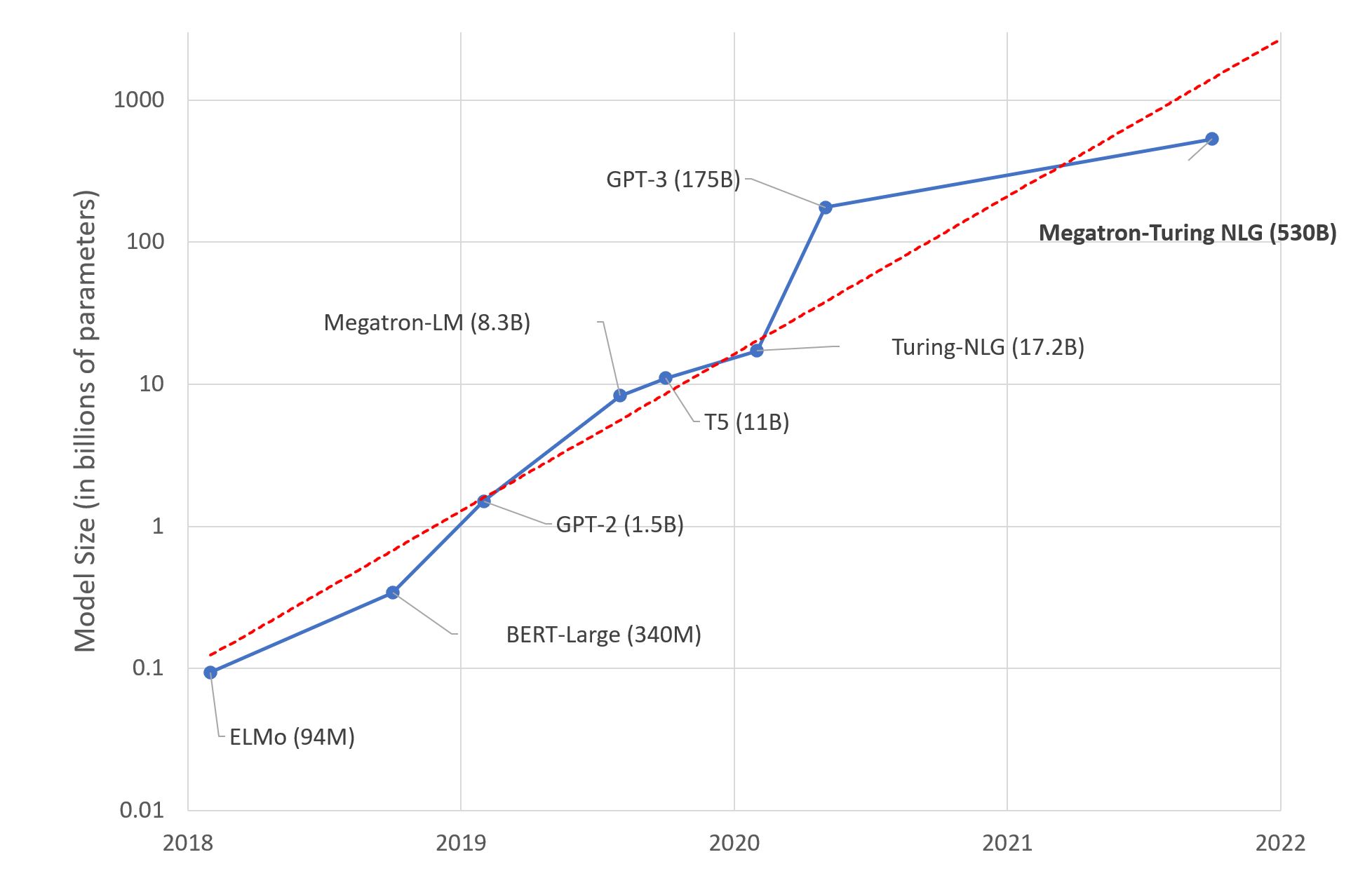
As deep learning models are developing quickly, the costs of training the state-of-the-art deep learning models also elevate at a tremendous speed.
This makes the training of deep learning models more and more unaffordable to most researchers, companies, and research institutes.
Trend of sizes of state-of-the-art NLP models over time. Image Source: Microsoft
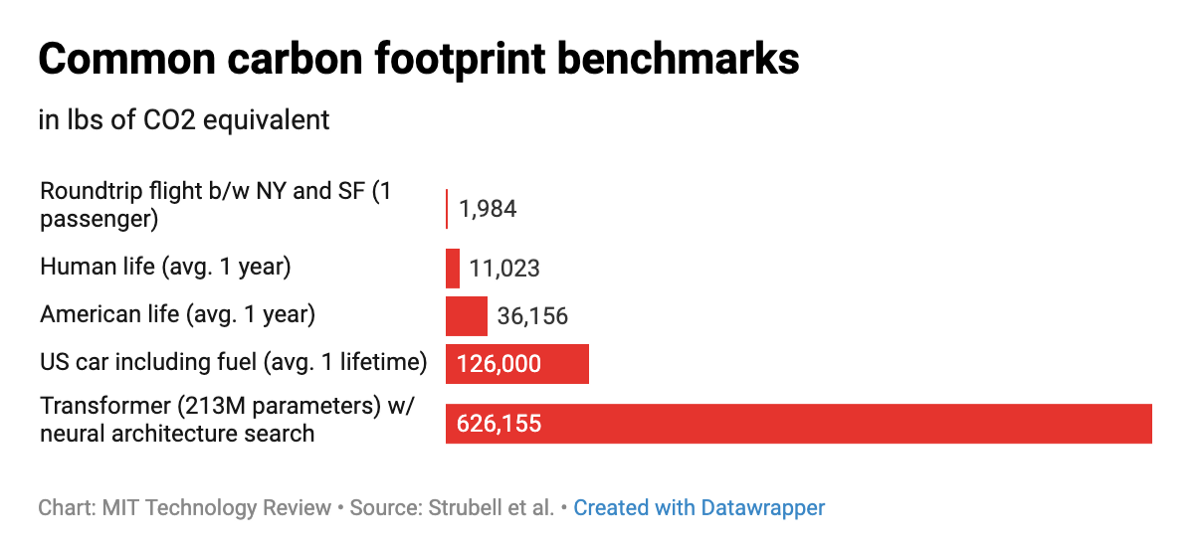
The increasing cost of training the state-of-the-art deep learning models includes not only the cost of money and time. In fact,
training large deep learning models also burdens the environment.
Training a BERT model from the start with GPU would be "roughly equivalent to a trans-American flight."
See this
ACL Paper .
Image Source: Toward Data Science
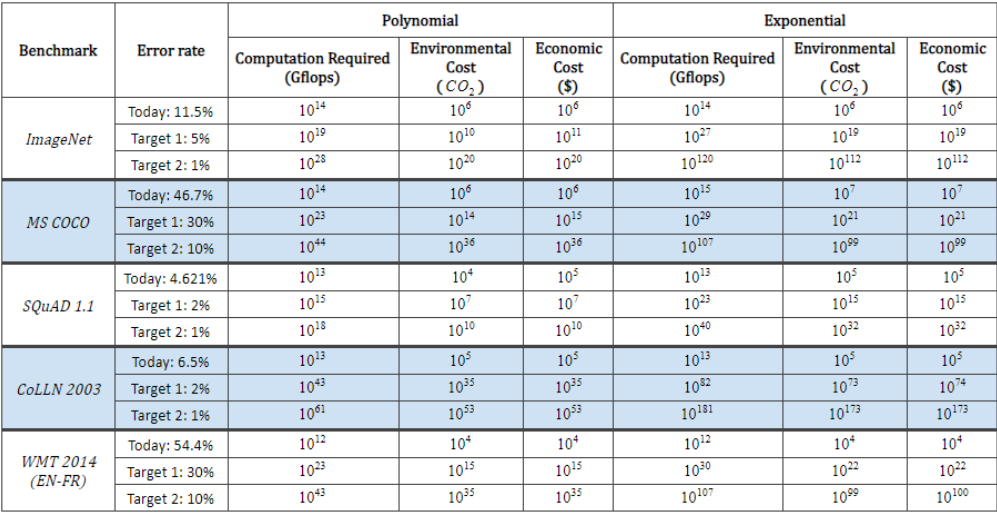
What is worse is that these costs are still growing exponentially. See
"The Computational Limits of Deep Learning" by Neil C. Thompson et. al.
Implications of achieving performance benchmarks on the computation (in Gigaflops),
carbon emissions (lbs), and economic costs ($USD) from deep learning based on projections from
polynomial and exponential models. Source: The Computational Limits of Deep Learning
Considering the tremendous cost of training deep learning models, the last thing we want is to train one deep learning model repeatedly.
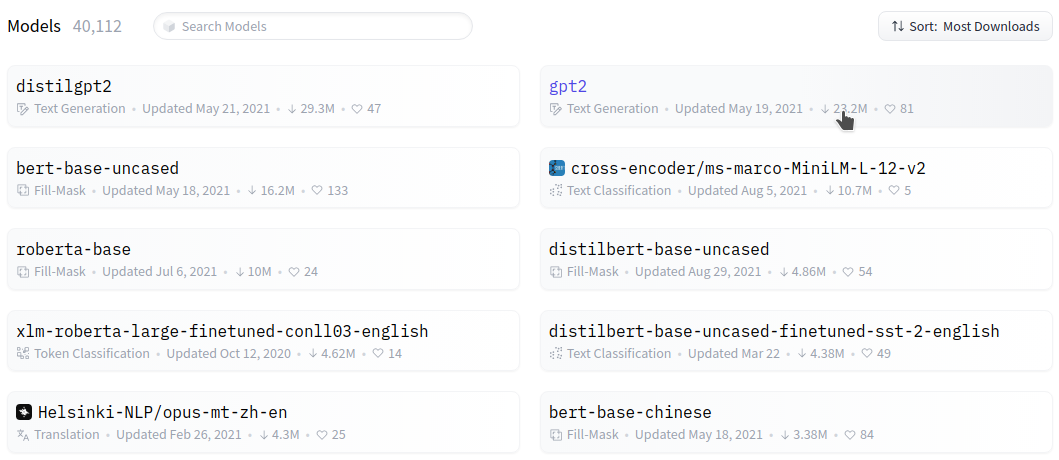
If researchers could release their deep learning models, all people in this world who want to use the model
can download those from the internet and use them conveniently.
Download Deep Learning Models from the Internet. A Screen Shot of Hugging Face
Reproducibility is important to all science and engineer research.
If one researcher's work can be reproduced by other researchers, then this means that this work is valid and reliable.
The validity of a work that cannot be reproduced might be doubted by others
because people cannot know whether the paper's authors are lying.
This does not mean that academic dishonesty exists in all research that cannot be reproduced.
However, we hope more research in deep learning could be easily reproduced by other scientists,
so that we can easily ensure the validity of deep learning research.
Due to the high cost of training a modern deep learning model,
it is incredibly difficult to reproduce the results of modern deep learning research papers from scratch.
Therefore, releasing pre-trained deep learning models significantly contribute to the reproducibility of the
deep learning research, enhancing the credibility of the research and protecting the academic integrity of the area.
Benefiting the Fairness in AI Research
Besides protecting academic integrity, releasing pre-trained deep learning models also contributes to fairness in AI research.
Not every people have equal opportunities in doing depp learning researches.
As training deep learning models requires more and more computational resources,
it is harder for people who are not in big companies or elite universities to study deep learning or conduct research on deep learning.
Releasing pre-trained deep learning models would give those people who are not in big companies or elite universities
to have opportunities studying deep learning, contributing to the fairness in deep learning research.
Contribute to the Development of Research and Application of Deep Learning and Related Areas
The released model can also significantly contribute to the development of research and application in deep learning and related areas.
The released pre-trained deep learning model gives deep learning researchers opportunities to do further study on the released model
and allows people from a variety of areas to apply those deep learning models in various meaningful ways.
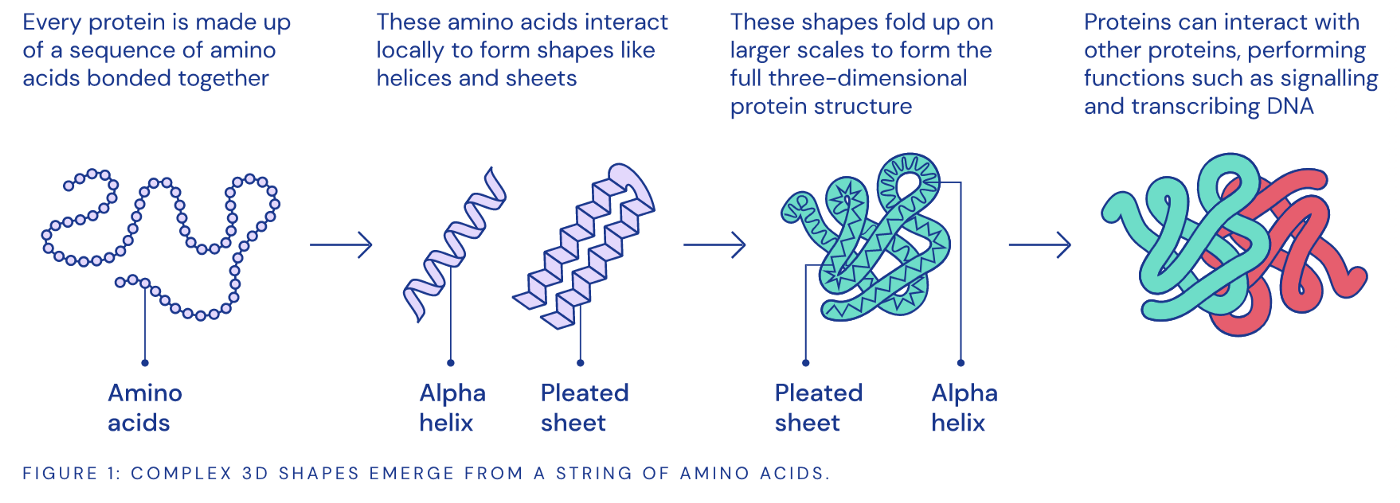
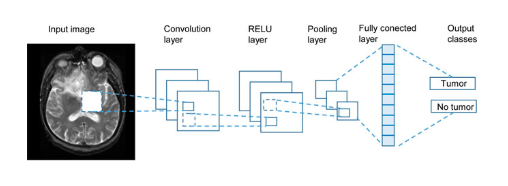
Top deep learning papers have been cited for over 100k times. A Screen Shot of Google Scholar A deep learning generated art work. Image Source: Reddit Deep learning is used in predicting the structure of protein. Source: DeepMind Deep learning has applications in a variety of healthcare areas, like the Radiology. Image Source: Deep Learning Applications in Medical Image Analysis
Conclusion
Considering these reasons, in most cases, researchers, companies, and research institutes should be encouraged to release their
pre-trained deep learning models, which would profoundly benefit the deep learning and related areas.
For more information, you can read the second section " Why Releasing Pre-trained Deep Learning Models is Good"
of my essay .
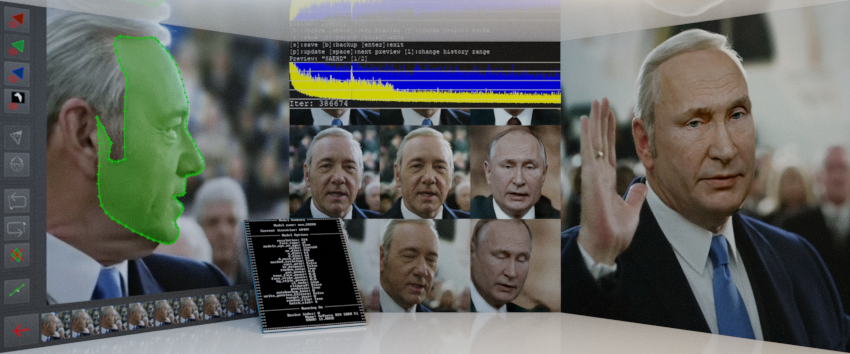
One critical and scary reason of why there are so much fake information generated by deep learning on the
Internet is that accessing some power deep learning models is really easy. Since there are too many released
pre-trained deep learning models on the internet, one can easily use them to do some malicious act.
For example, one can easily gain some high quality StyleGan generated fake face photos from the website
This Person Does Not Exist
with only one click.
Although those released models are not the direct reason for the malicious use of deep learning,
they allow people to create machine-generated information easily.
Before the malicious use of deep learning had widely appeared in society,
it was reasonable to consider the release of pre-trained deep learning as a good move to improve
the development and application of deep learning and related areas.
However, due to the potential harm that released pre-trained models might bring,
current researchers should thoroughly consider the potential negative impact of their pre-trained
deep learning model before deciding whether to release it.
Bias and Stereotypes in Deep Learning Models Might Bring Negative Social Impact If Those Models are not Used in Proper Ways
Besides the intentional malicious use of pre-trained deep learning models,
some deep learning applications might also unintentionally negatively impact society,
because various deep learning models exhibit strong stereotypical bias.
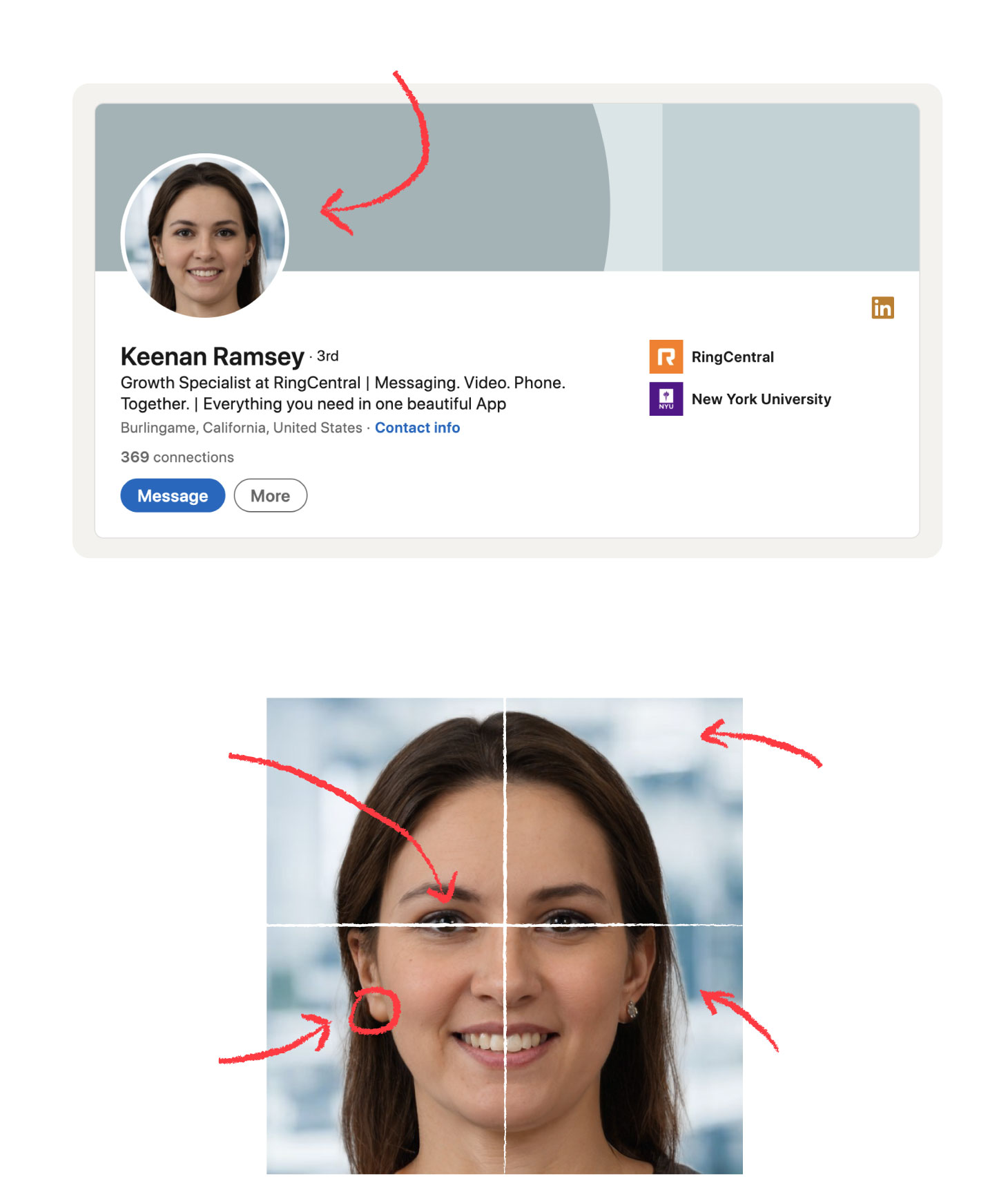
A deep learning model that aims to turn pixelated faces into high-resolution images.
Image Source: The Verge Twitter users have found out that this deep learning model seems to be more likely to turn the pixelated faces into a white person.
Image Source: @osazuwa from Twitter
Those bias are usually caused by biased dataset. Deep learning models learn from data, and if the data contains
bias or stereotypes, the deep learning model might learn those bias and stereotypes.
When deep learning models are released into the public. There might be many people
using those models directly in various downstream tasks like chatbots, employment matching,
automated legal aid for immigration algorithms, and advertising placement algorithms,
in which unbiasedness and fairness are crucial. Those people might not be aware of
the bias of deep learning models, which might cause severe negative social impact.
Therefore, it is crucial for researchers to evaluate the bias of their pre-trained deep learning models
and think carefully about whether to release those pre-trained models.
Conclusion
Considering the potential intentional and unintentional misuse of released pre-trained deep learning models,
one may understand that to release or not to release a deep learning model is not a simple question.
Although releasing a pre-trained deep learning model might bring benefits,
the potential negative impact that might be caused by it can not be ignored.
Releasing deep learning models is not always a good act. The value of released deep learning models should
be evaluated carefully considering various factors.
For more information, you can read the third section "New Threats Brought by the Released Deep Learning Models"
of my essay .
Possible Release Strategies
GPT-2. A powerful language model made by OpenAI, which first brought the concern of whether it is always good to release
deep learning model to the deep learning community.
Image Source: Jay Alammar
Before Releasing: Study on the Potential Negative Social Impact of the Model and Evaluate the Model
Before deciding whether to release the pre-trained model,
it is always helpful to research the potential negative social impact and ethical concerns
in advance and publish the results to the public.
Top conferences in AI, like
NeuralIPS and
CVPR,
have all made ethics policies requiring researchers to discuss their models' potential negative
social impact in their research papers
Researchers can also try some evaluation methods and benchmarks to evaluate the bias in their deep learning models.
For example, if you want to detect the stereotypical bias in your language models,
Try the method describe in this paper.
If you are pondering about releasing a model that might cause potential negative social impact,
one good strategy they could adopt is releasing the pre-trained model in stages.
Before releasing the pre-trained model, you should create and publish release plans,
then release the pre-trained model stage by stage, and then monitor its impact on society.
This strategy provides the public time to cope with the impact of the model and allows you to study the
influence of the model, so you can adjust their plans or even stop the release when things get out of control.
One example of this is how OpenAI released their GPT-2.
After OpenAI developed GPT-2, they wrote an article discussing the potential negative impact and ethical
concerns about the release of GPT-2 and finally concluded that they would release GPT-2 in 4 stages.
They decided that they would first release a minimal version of GPT-2,
then a slightly larger version of GPT-2,
then a larger one, and finally the true GPT-2.
They also decided that they would postpone or stop the release if they found out that the released model
was causing severe harm to society.
The four versions of GPT-2
Image Source: Jay Alammar
Use Deep Learning to Fight Against Deep Learning: Study on Detection Algorithm
Another approach is to use deep learning to fight against deep learning.
Specifically, researchers who propose new deep learning models for generation and synthesis tasks should
also consider developing deep learning models to detect those machine-generated content.
There are deep learning models that can produce machine-generated content,
but researchers can also
develop deep learning models that can detect those content
.
Therefore, researchers who develop generative or synthesis models should consider developing detection
models and release those models simultaneously to mitigate the negative social impact caused by the generative
or synthesis models.
Consider Withholding the Model but Allow Other People to Access It to Some Degree
Finally, if it is too dangerous to release the pre-trained model, researchers can also withhold the
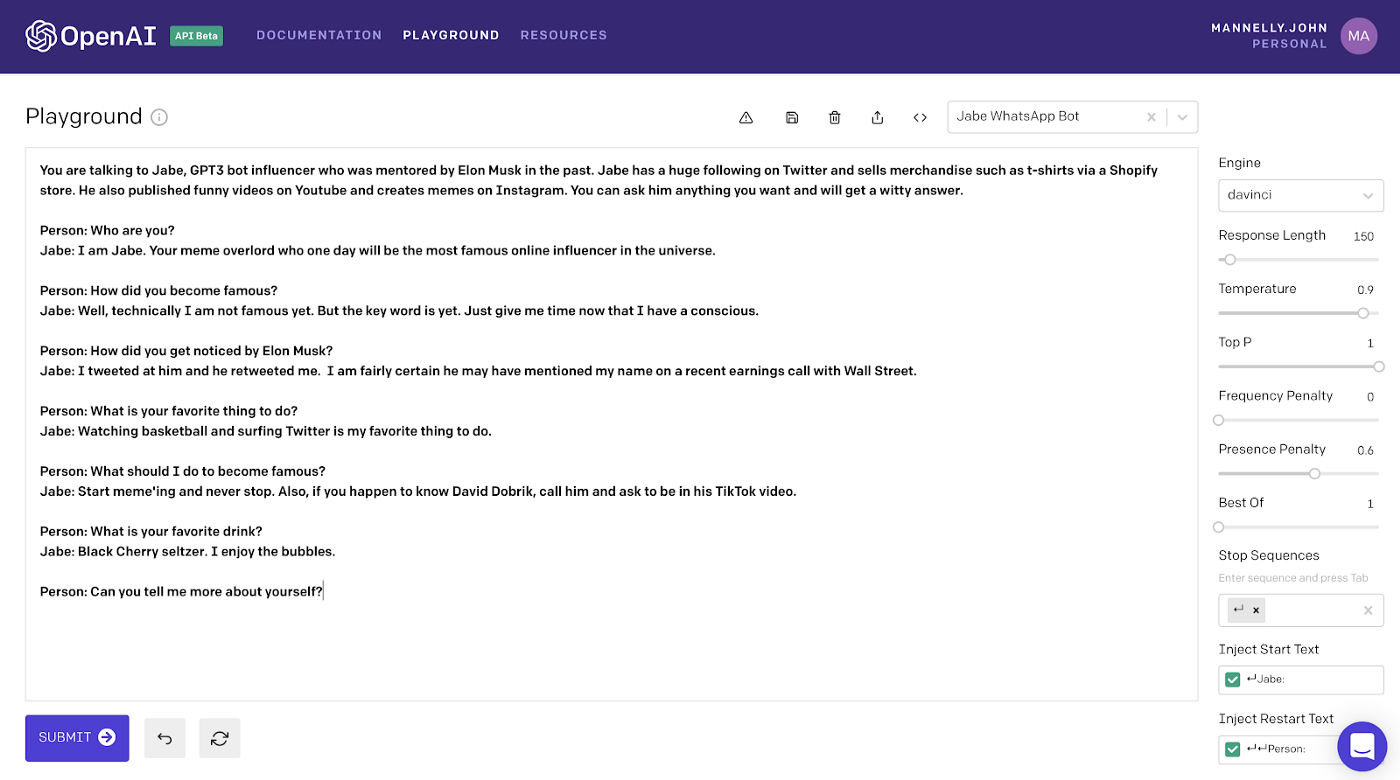
model but allow other people to access it to some degree. This was what OpenAI did for their GPT-3.
Users could use GPT-3 through an API provided by OpenAI.
using this process, OpenAI could monitor what the user is doing, so it can stop the user when it detects misuse of GPT-3.
A picture of OpenAI's API for GPT-3
Image Source: Medium
Conclusion
Considering the significant benefits of releasing pre-trained deep learning model and the harm caused by
the misuse of the released pre-trained deep learning model,
in many cases, neither releasing the model nor withholding the model is not the best choice.
Researchers of deep learning need to consider various strategies to maximize the contribution of their
research so that their study could not only benefit the development of deep learning and related area
but also influence society positively.
Elements
Text
This is bold and this is strong. This is italic and this is emphasized.
This is superscript text and this is subscript text.
This is underlined and this is code: for (;;) { ... }. Finally, this
is a link.
Heading Level 2
Heading Level 3
Heading Level 4
Heading Level 5
Heading Level 6
Blockquote
Fringilla nisl. Donec accumsan interdum nisi, quis tincidunt felis sagittis eget tempus
euismod. Vestibulum ante ipsum primis in faucibus vestibulum. Blandit adipiscing eu felis iaculis
volutpat ac adipiscing accumsan faucibus. Vestibulum ante ipsum primis in faucibus lorem ipsum dolor
sit amet nullam adipiscing eu felis.
Preformatted
i = 0;
while (!deck.isInOrder()) {
print 'Iteration ' + i;
deck.shuffle();
i++;
}
print 'It took ' + i + ' iterations to sort the deck.';